How well do different adaptive algorithms perform?¶
This script will see how the adaptive algorithm out-preforms the passive algorithm.
It does this by seeing how many rankings are considered the funniest ranking. For each caption we have a mean and a standard deviation. If the first rated caption has mean \(\mu_1\) and std.dev. of \(\sigma_1\), we want how many captions \(i\) have \(\mu_i + \sigma_i > \mu_1 - \sigma_1\).
Metrics¶
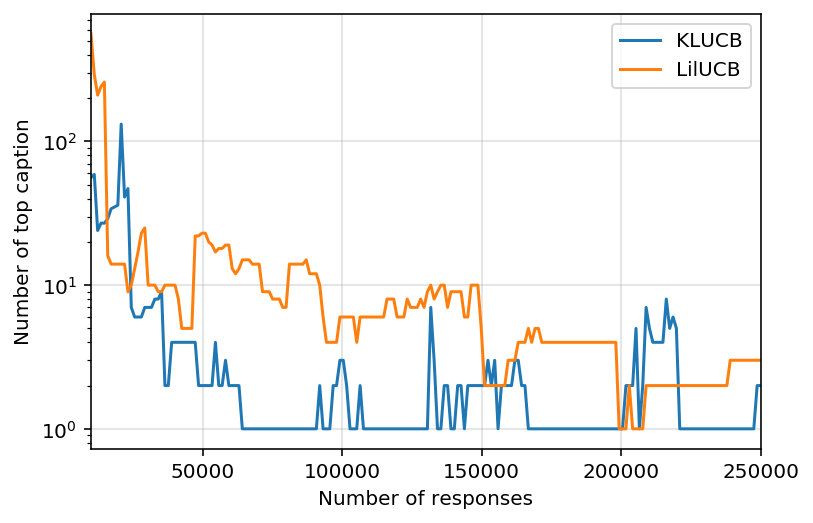
Number of captions that could be the funniest caption
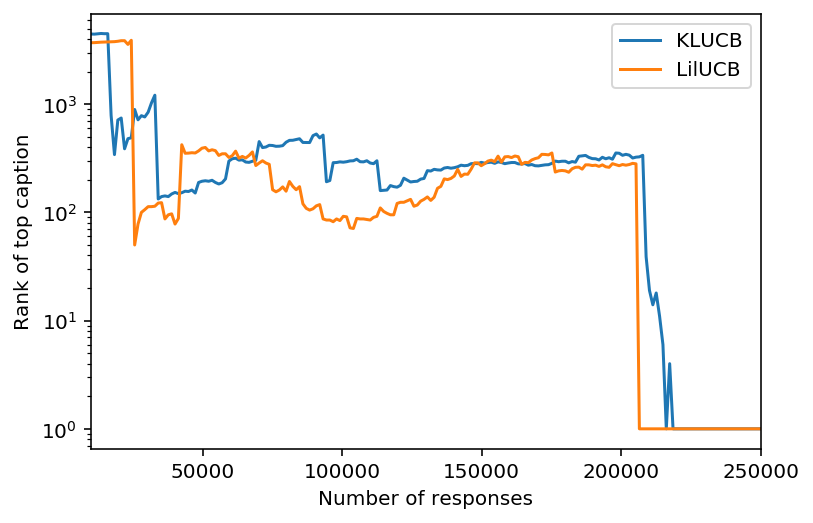
Rank of caption found to be the funniest at the end
[1]:
import numpy as np
[2]:
import caption_contest_data as ccd
[3]:
df1 = ccd.responses("559-active")
df2 = ccd.responses("559-passive")
df1.target_id.nunique(), df2.target_id.nunique()
[3]:
(5012, 138)
[4]:
import pandas as pd
df = df1
df.iloc[0]
[4]:
alg_label LilUCB
network_delay 1.96677
participant_uid c84f9a4715e586b920096d5d1c0b38_xofXRJCicRqzuVa...
response_time 4.947
target Sort of takes the fun out of it.
target_id 4254
target_reward 3
timestamp_query_generated 2017-03-12 04:45:35.389856
label funny
contest 559
filename 559-active-responses.csv
Name: 0, dtype: object
[5]:
df.dtypes
[5]:
alg_label object
network_delay float64
participant_uid object
response_time float64
target object
target_id int64
target_reward int64
timestamp_query_generated datetime64[ns]
label object
contest object
filename object
dtype: object
[6]:
df.memory_usage().sum() / 1024**2, "MB"
[6]:
(41.95037841796875, 'MB')
[7]:
df1.timestamp_query_generated.min(), df2.timestamp_query_generated.min()
[7]:
(Timestamp('2017-03-06 15:01:46.733847'),
Timestamp('2017-03-07 20:07:07.962230'))
[8]:
start = pd.Timestamp('2017-03-06 15:01:46.733847')
time_diff1 = df1.timestamp_query_generated - start
time_diff2 = df2.timestamp_query_generated - start
time_d1 = time_diff1.apply(lambda x: x.total_seconds() / (60 * 60 * 24))
time_d2 = time_diff2.apply(lambda x: x.total_seconds() / (60 * 60 * 24))
[9]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
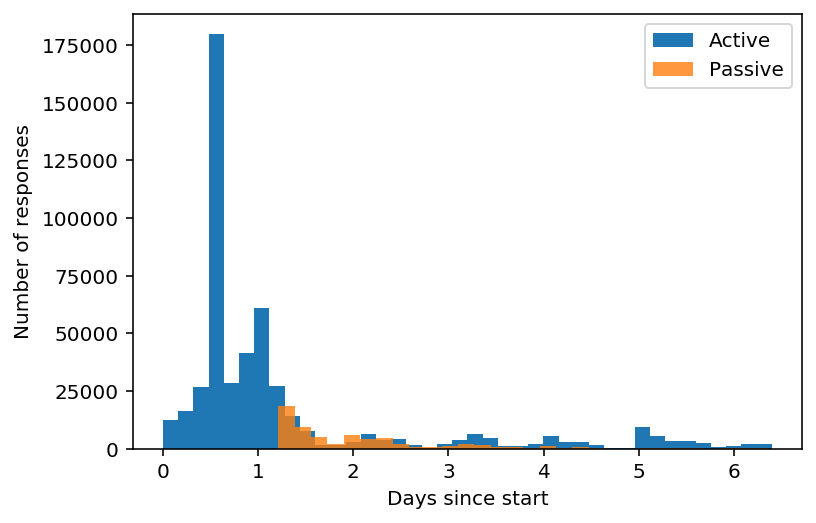
time_d1.plot.hist(ax=ax, bins=40, label="Active")
time_d2.plot.hist(ax=ax, bins=30, alpha=0.8, label="Passive")
ax.legend(loc="best")
ax.set_xlabel("Days since start")
ax.set_ylabel("Number of responses")
[9]:
Text(0, 0.5, 'Number of responses')
[10]:
df.sort_values(by="timestamp_query_generated", inplace=True)
[11]:
import caption_contest_data._raw as raw
[12]:
scores = df.pivot_table(
index="target_id",
values="target_reward",
columns="alg_label",
aggfunc=np.mean,
)
top_scores = {alg: (scores[alg].idxmax(), scores[alg].max()) for alg in ["KLUCB", "LilUCB"]}
top_scores
[12]:
{'KLUCB': (1559, 1.7674418604651163), 'LilUCB': (387, 1.8341463414634147)}
[13]:
num_responses = df.pivot_table(
index="alg_label",
values="target_reward",
aggfunc=len,
)
num_responses
[13]:
| target_reward | |
|---|---|
| alg_label | |
| KLUCB | 250564 |
| LilUCB | 249300 |
[14]:
def get_stats(df, alg_label, num_responses, top_id, top=10):
idx = (df.alg_label == alg_label)
s = df[idx]
idx = np.arange(len(s)) <= num_responses
show = s.iloc[idx]
counts = show.pivot_table(
columns="label",
index="target_id",
values="response_time",
aggfunc=len,
)
count = counts.sum(axis=1)
counts.fillna(0, inplace=True)
score, prec = raw.score_and_prec(counts["unfunny"], counts["somewhat_funny"], counts["funny"], count)
stats = pd.DataFrame({"score": score, "prec": prec})
stats.sort_values(by="score", ascending=False, inplace=True)
top_rank = np.argwhere(stats.index == top_id).item() + 1
top_cap = stats.loc[stats.score.idxmax()]
num_top_captions = (top_cap["score"] - top_cap["prec"] < score).sum()
return {
"num_top": num_top_captions,
"top_in_top": top_id in stats.index[:10],
"top": top,
"num_responses": num_responses,
"alg_label": alg_label,
"top_rank": top_rank,
}
[16]:
data = []
for k, num_responses in enumerate(np.linspace(10e3, 250e3, num=200).astype(int)):
for alg_label in ["KLUCB", "LilUCB"]:
if k % 20 == 0:
print(k, num_responses)
datum = get_stats(df, alg_label, num_responses, top_scores[alg_label][0])
data.append(datum)
0 10000
0 10000
20 34120
20 34120
40 58241
40 58241
60 82361
60 82361
80 106482
80 106482
100 130603
100 130603
120 154723
120 154723
140 178844
140 178844
160 202964
160 202964
180 227085
180 227085
[17]:
show = pd.DataFrame(data)
[18]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
for alg in show.alg_label.unique():
show[show.alg_label == alg].plot(x="num_responses", y="top_rank", ax=ax, label=alg)
ax.set_ylabel("Rank of top caption")
ax.set_xlabel("Number of responses")
ax.set_yscale("log")
[19]:
fig, ax = plt.subplots()
for alg in show.alg_label.unique():
show[show.alg_label == alg].plot(x="num_responses", y="num_top", ax=ax, label=alg)
ax.set_ylabel("Number of top caption")
ax.set_xlabel("Number of responses")
# ax.set_xscale("log")
ax.set_yscale("log")
ax.grid(alpha=0.4)
[ ]: